5 techniques to fine-tune LLMs!!
LoRA,LoRA-FA,VeRA,Delta-LoRA,LoRA+ all of them explained !!
Fine-tuning large language models traditionally involved adjusting billions of parameters, demanding significant computational power and resources.However, the development of some innovative methods have transformed this process.Here’s a snapshot of five cutting-edge techniques for finetuning LLMs, each explained visually for easy understanding.
1. LoRA (Low-Rank Adaptation of Large Language Models)
Key Idea:LoRA introduces two low-rank matrices, A and B, that decompose the large weight matrix W of a model layer. Instead of updating the massive weight matrix W, the training updates only happen on these smaller matrices A and B.Details:Matrix W decomposition: The weight matrix W is decomposed into two smaller matrices A and B.
The matrix A has a low rank and contains the learning directions, and matrix B is responsible for the scaling
.Low-rank factorization: These low-rank matrices approximate the full rank of the weight matrix, making updates computationally cheaper while retaining model performance.Fewer parameters to train: Because LoRA uses smaller matrices, it reduces the number of trainable parameters significantly, leading to faster training with less resource consumption.
Mathematical formulation:W′=W+αAB
Where W’ is the updated weight, A and B are the low-rank matrices, and α is a scaling factor. The update is applied only to A and B, not the whole W.
Advantages:
Reduced memory footprint: Since updates happen only in A and B, LoRA uses less memory compared to traditional fine-tuning.
Maintains performance: Despite fewer parameters being trained, LoRA retains performance comparable to full model fine-tuning.
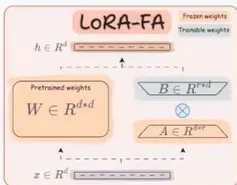
2. LoRA-FA (Frozen-A LoRA)Key Idea:LoRA-FA is an extension of LoRA that freezes the matrix A while training. This further reduces the number of trainable parameters and saves memory since only matrix B is updated during training.
Details:Matrix A is frozen: In this version, matrix A is initialized but not updated during training, while B is the only trainable parameter. This decreases the computational load.
Memory efficiency: By freezing A, memory consumption during training is minimized even further, reducing activation memory.
Mathematical formulation:W′=W+α⋅B
Where A is frozen and not part of the update process.Advantages:Even fewer parameters to update: Reduces the number of trainable parameters beyond regular LoRA.Decreased memory footprint: With only B being updated, it further reduces memory requirements.Ideal for low-resource environments: Freezing A makes it particularly useful when computational resources are limited.
3. VeRA (Very Reduced Adaptation)Key Idea:VeRA goes one step further by fixing both matrices A and B and focusing on training only tiny scaling vectors within each layer. This approach is designed to be highly memory-efficient.Details:Fixed matrices: Both A and B are fixed and shared across all layers, meaning they are not trainable.
Scaling vectors: Instead of training A and B, small trainable scaling vectors are used in each layer to adjust the model’s output.
Super memory-efficient: Since A and B are shared across all layers and not updated, the memory overhead is significantly reduced.
Mathematical formulation:W′=W+γ⋅
(A⋅B)Where γ is the trainable scaling vector, and A and B are fixed
Advantages:
Minimal memory usage: Fixing A and B and training only the scaling vectors makes it ideal for extremely memory-constrained environments.Efficient: Provides a good balance between parameter efficiency and model performance without sacrificing too much in terms of accuracy.
4. Delta-LoRA (Delta Low-Rank Adaptation)Key Idea:Delta-LoRA builds on the original LoRA approach but introduces the concept of adding a difference (delta) between the products of matrices A and B across training steps. This method allows the model to dynamically adjust its weights over training, providing more flexibility.Details:Dynamic updates: Instead of updating A and B linearly, Delta-LoRA accumulates the delta (difference) between the products of A and B from previous steps.Adaptability: This approach makes Delta-LoRA more flexible and adaptable to the nuances of training, allowing for more controlled updates.Mathematical formulation:W′=W+α⋅(AB+Δ(AB))Where Δ(AB) represents the delta of the products over training steps.Advantages:Dynamic control: The use of delta allows more controlled parameter updates, making training more flexible.Faster convergence: By incorporating the delta, this approach can lead to faster convergence in certain tasks.
5. LoRA+ (Enhanced LoRA)Key Idea: LoRA+ introduces a tweak to the original LoRA by assigning a higher learning rate to matrix B, leading to faster and more effective learning.Details:Learning rate optimization: LoRA+ gives a higher learning rate to matrix B, which helps accelerate training, especially in tasks requiring fast adaptation.Faster convergence: By allowing B to adapt more quickly, LoRA+ achieves better performance faster.
Mathematical formulation:W′=W+αAB
Where B is updated with a higher learning rate compared to A.
Advantages
Faster learning: With matrix B having a higher learning rate, LoRA+ adapts faster than traditional LoRA.
More effective training: Especially useful when training time is limited, as this method improves learning speed without major sacrifices to accuracy.

All these methods aim to fine-tune large language models or deep learning models in a more efficient and memory-friendly manner. By focusing on updating smaller, low-rank matrices, or introducing controlled updates (as in Delta-LoRA), they provide ways to train models efficiently while maintaining high performance. Depending on the scenario — whether you have limited computational resources or need faster learning — you can choose the appropriate method from this set.

